Įvadas
Statistika – tai valstybės ribose esančių reiškinių padėtis, jų būklės atspindys. Šiuo metu statistika suprantama taip: tai mokslas, nagrinėjantis masinius socialinius ekonominius bei kitus reiškinius, kiekybiniu aspektu su jų kokybiniu turiniu vietos ir laiko sąlygomis.
Statistikos objekto ypatybės sąlygoja jos metodą. Statistikos metodas – tai būdų, priemonių visuma masinių procesų dėsningumams tirti.
Statistikos metodai glaudžiai tarpusavyje susiję, jie įgalina logiškai nuosekliai atskleisti tiriamo objekto turinį. Jos metodų vienybę ir sąryšį nulemia tai, kad statistika visuomeninius reiškinius ir procesus tiria tarpusavyje susijusius, nuolat besivystančius, dinamiškus, kaip atsitiktinumo ir būtinumo dialektinį sąryšį. Tai leidžia statistikai pažinti masinius visuomeninius reiškinius tokius, kokie jie yra, o ne kokie atrodo.
Pagrindinis mokslinis principas – tarpusavyje susijusių visumos faktų tyrimas. Dialektinio metodo požiūriu nė vienas reiškinys negali būti pažintas, suprastas jį nagrinėjant izoliuotai. Todėl vienas iš svarbiausių statistikos uždavinių yra priežastinių ryšių atskleidimas, jų išmatavimas.
Antra vertus, dialektinis metodas reikalauja reiškinius tirti jiems judant, kintant, vystantis. Čia ypač svarbus vaidmuo tenka kiekybinių pakitimų perėjimo į naują kokybę dėsniui.
Visuomeniniai reiškiniai nėra vienarūšiai, jie kiekybiškai skirtingai išreiškiami. Statistikos uždavinys – atskleisti naują kokybę, kurią nulėmė kiekybiniai pakitimai.
Taigi dialektinis materializmas, kaip bendrasis metodas, duoda kryptį kurti specifinius statistinius metodus, kurie yra ne tik priemonė objektyviai informacijai apie tikrovę gauti, bet ir instrumentas nuodugniau jai pažinti.
STATISTIKOS TYRIMO METODAI
Tiriant masinius visuomeninius reiškinius statistikos metodais, pereinami keturi etapai, kuriuose atitinkamai taikomos keturios statistikos metodų grupės (statistinio stebėjimo, statistinės medžiagos suvedimo ir analizės, analizės rezultatų įvertinimo). Šie keturi tyrimo etapai atliekami nuosekliai, jie yra glaudžiai tarpusavyje susiję. Kiekviename etape taikomi specifiniai tyrimo metodai.
Pirmame tyrimo etape naudojami masiniai stebėjimai. Jie atliekami taikant įvairias stebėjimo formas, rūšis ir būdus priklausomai nuo tiriamo objekto specifikos. Tik atliekant masinius stebėjimus, galima atskleisti ir ištirti dėsningumus bei tendencijas.
Antrame tyrimo etape susisteminami ir sutvarkomi stebėjimo metu gauti duomenys. Šiame etape taikomi surinktų duomenų kontrolė, rūšiavimas, grupavimai, apibendrinančių rodiklių apskaičiavimas, statistinių lentelių suvedimo bei grafikų vaizdavimo metodai.
Trečiame tyrimo etape atliekama gautų rezultatų analizė, t. y. nustatomi reiškinių santykiai, ryšiai bei vystymosi tendencijos. Tam tikslui taikomi tokie specifiniai statistikos metodai kaip koreliacijos bei regresijos, dinamikos eilučių, indeksų ir kt. Ši analizė gali būti dviejų lygių: gautų duomenų tikslumo vertinimas (parametrų įvertinimo, statistinių hipotezių patikrinimo metodai) ir dalykinė tiriamo objekto būklės analizė.
Ketvirtame tyrimo etape pateikiamos išvados apie tiriamo reiškinio objekto būklę (ekonominis interpretavimas), prognozės ateičiai, gali būti rekomendacijos.
Masinių stebėjimų būtinumą sąlygoja didžiųjų skaičių dėsnis. Jis atskleidžia atsitiktinumo ir būtinumo dialektiką, t. y. kad dėsningumas išryškėja tik masiškai stebint. Tokio stebėjimo metu atskirų vienetų reikšmių nukrypimai vienas kitą „kompensuoja“, panaikina, o vidutinė reikšmė jau nėra atsitiktinė ir gali būti nustatyta gan tiksliai. Esant masiniams stebėjimams, išryškėja įtik pagrindinių, esminių veiksnių įtaka ir neatsispindi .antraeilių, šalutinių priežasčių poveikis.
Šio dėsnio veikimas tuo aiškesnis, kuo didesnis stebėjimų skaičius. Pavyzdžiui, kiekvienos šeimos narių skaičius atskirai gali būti traktuojamas kaip atsitiktinis. Jis negali atspindėti tam tikro regiono šeimos dydžio. Tačiau tiriant .daugiau šeimų, vidutinis šeimas narių skaičius vis labiau ryškėja, stabilizuojasi. Pakankamai tiksliai šis vidurkis gali būti nustatytas tik atlikus masinį faktų registravimą.
Matematiškai didžiųjų sikaičių dėsnis išreiškiamas keliomis teoremomis. Pavyzdžiui, įrodoma, kad kuo didesnis stebėjimų skaičius, tuo tiksliau nustatytos charakteristikos atspindi tiriamos visumos savybes, dėsningumus.
Su didžiųjų skaičių dėsnio sąvoka susijęs statistinis dėsningumas išplaukia iš jo turinio. Statistinis dėsningumas yra viena iš reiškinių visuotinio ryšio formų. Tai esminių tarpusavio ryšių sąlygotas reiškinių ir procesų vyksmo pobūdis. Jis išryškėja tik verkiant didžiųjų skaičių dėsniui. Priešingai dinaminiam dėsningumui, kai vienų veiksnių reikšmes atitinka griežtai apibrėžtos priklausomų dydžių reikšmės ir kai priklausomų dydžių santykiai tiksliai gali būti nustatyti kiekvienu konkrečiu atveju, statistinis dėsningumas išryškėja tik stebint daug to paties tipo reiškinių. Kiekvienu konkrečiu atveju reiškinio pasirodymas turi tikimybinį pobūdį.
Pavyzdžiui, negalima tvirtinti, kad jei Petraitis dirba tekintoju penkiolika metų, tai jo tarifinė kategorija bus ketvirta, penkta arba šešta. Tačiau jeigu ištirsime didelį tekintojų skaičių, tai nesunkiai pastebėsime, kad tekintojo kvalifikacija priklauso nuo darbo stažo. Galima teigti, (kad tai yra dėsninga.
Be to, priklausomybę galima išreikšti ir kiekybiškai. Pavyzdžiui, apskaičiuoti vidutinę tarifinę kategoriją tekintojų, kurių darbo stažas penkeri, dešimt, penkiolika ir daugiau metų, t. y. kiekvienos tekintojų grupės pagal darbo stažą. Ir tai bus tikslu tik ištirtai tekintojų visumai.
Statistinis dėsningumas išreiškia būtinumo ir atsitiktinumo vienybę. Tirdami statistinius dėsningumus, visada randame atsitiktinumo elementų. Tai galima paaiškinti tuo, kad tikrovės pažinimo procesas yra begalinis.
Mokslo tiesa nėra absoliuti, o greičiau iš dalies apytikslė ir laikina. Mokslui žengiant į priekį, atskleidžiamos vis naujos reiškinio pasirodymo priežastys. Tačiau ne visos jos žinomos, o tai ir paaiškinama statistiniu dėsningumu, kuris išryškėja tik atliekant masinį stebėjimą ir nepastebimas tiriant pavienius faktus.
Kitaip tariant, kiekvienas dėsningumas yra statistinis, o dinaminis (pvz., determinuotas ryšys) – tik apytikrė reiškinių ir procesų sąveikos išraiška. Netgi klasikinės mechanikos dėsniai, kurie buvo laikomi visiškai tiksliais, pasirodė esantys tik santykiniai.
Atliekant mokslinį tyrimą ir operuojant konkrečiais duomenimis, nustatomi vadinamieji empiriniai dėsningumai, t. y. faktų tvarkingas pasikartojamumais, konkreti statistinio dėsningumo pasireiškimo forma. Tiriant jų pasireiškimo formas, galima pažinti reiškinių esmę ir turinį.
Statistinio dėsningumo atskleidimas prasideda nuo hipotezės iškėlimo. Hipotezė iškeliama kaip prielaida, kaip spėjimas, padiktuotas tam tikros naujuose faktuose pastebėtos tvarkos, kur negali būti primestas visiškas atsitiktinumas. Norint ją patikrinti, reikia masinių duomenų. Vadinasi, mokslas žengia pirmyn, pereidamas vis prie tikresnių žinių. Šioje hipotezių iškėlimo ir patikrinimo grandinėje labai svarbus statistikos vaidmuo.
Sistemindama, apdorodama ir analizuodama masinių stebėjimų duomenis, statistika plačiai naudoja matematinės statistikos metodus. Jie pritaikomi tiek, kiek masiniai reiškiniai sudaro tam tikra prasme aibes viena rūšių elementų, kurių kiekybinės charakteristikos tarpusavyje nepriklausomos, t. y. tarp jų nėra determinuoto ryšio. Tokiems masiniams reiškiniams tirti naudojami vidurkiai, variacijos rodikliai ir pasiskirstymo eilučių teorija, hipotezių tikrinimas, atrankinis, koreliacijos, regresijos ir daugiamatės analizės metodai (daugiamačiai grupavimai, faktorinė analizė ir kt.).
Statistikos, kaip visuomeninio mokslo, pagrindinis vaidmuo pasireiškia tuo, kad kiekvienu konkrečiu atveju reikia parinkti tuos rodiklius, jų skaičiavimo būdus ir metodus, kurie labiausiai atitinka reiškinių socialinį ekonominį turinį; be to, reikia juos pritaikyti atsižvelgiant į konkrečias sąlygas, kad būtų galima nuodugniau pažinti tiriamų reiškinių esmę. Pavyzdžiui, sakykim, kad keli darbininkai gamina tas pačias detales visą darbo dieną. Kiekvieno darbininko sugaištas laikas vienai detalei pagaminti bus nevienodas. Individualias darbo laiko sąnaudas pažymėkime Xi, x2, x3,…, xn. Matematiškai, remiantis šiais duomenimis, galima apskaičiuoti bet kurį vidurkį: aritmetinį, geometrinį, harmoninį ir kitus.
Tačiau, norint nustatyti vidutines (tipiškas) darbo laiko sąnaudas vienai detalei pagaminti, negalima naudoti nei aritmetinio, nei geometrinio vidurkių, kadangi tai neatitinka šio rodiklio turinio. Šiuo atveju taikytinas harmoninis vidurkis. Tik šis vidurkis atitinka darbo laiko sąnaudų vienai detalei pagaminti turinį.
Vadinasi, statistika universalių matematinės statistikos metodų negali taikyti formaliai, t. y. nepriklausomai nuo socialinių ekonominių reiškinių turinio, savybių bei ryšių, kaip objektyvaus jų pagrindo.
Tirdama masinius reiškinius ir procesus, statistika naudoja specifines sąvokas ir kategorijas: didžiųjų skaičių dėsnį, statistinį dėsningumą, požymį, statistinę visumą, variaciją, rodiklį ir kt. Su pirmomis dviem sąvokomis susipažinome anksčiau. Suprasti kitas sąvokas ir kategorijas taip pat labai svarbu. Be jų mes negalėsime suprasti statistikos mokslo turinio. Kaip ir kitų mokslų, taip ir statistikos sąvokose ir kategorijose yra sutelkiamos pagrindinės žinios, ir nors sąvokoje išskiriama tik bendrybė, be jos mes negalėsime paaiškinti konkrečių reiškinių ir procesų ypatybių. Trumpai apžvelgsime kitas statistikos sąvokas ir kategorijas.
Požymis – reiškinių arba procesų charakteringas bruožas, savybė arba ypatybė, kuri gali būti apibūdinta statistiniais dydžiais, t. y. stebima ir išmatuota. Pavyzdžiui, darbininko požymiai tokie: lytis, amžius, profesija, darbo stažas, tarifinis atlygis, mėnesinis darbo užmokestis, dalyvavimas racionalizatorių veikloje ir t. t.
Požymius galime suskirstyti į kiekybinius ir kokybinius, nors toks skirstymas yra sąlyginis, nes nėra griežtos ribos tarp jų.
Kiekybiniais (variaciniais) požymiais vadiname tokius, kurių reikšmės viena nuo kitos skiriasi apibrėžtu, išmatuojamu dydžiu (amžiumi, darbo stažu, tarifiniu atlygiu, mėnesiniu darbo užmokesčiu) .
Kokybiniais (atributyviniais) vadiname kiekybiškai neišreikštus požymius (lytį, profesiją). Svarbią vietą statistikoje užima atskiras atributyvinių požymių atvejis – alternatyviniai požymiai, kurie gali įgyti tik viena kitai priešingas dvi reikšmes (dalyvauja racionalizatorių judėjime arba nedalyvauja, įvykdo išdirbio normas arba neįvykdo).
Pagal statistinio tyrimo tikslo svarbą požymiai skirstomi į esminius ir neesminius.
Tyrimo metu išskiriami esminiai (pagrindiniai) požymiai, pagal kuriuos nustatomas reiškinių tipas. Remiantis jais, atliekami grupavimai, nustatomi jų tarpusavio ryšiai ir pan. Požymių svarbą galiausiai sąlygoja tyrimo tikslas.
Statistinė visuma – tai objektų arba reiškinių, egzistuojančių laike ir erdvėje, panašių pagal savo turinį, turinčių bendrų požymių ir besiskiriančių pagal jų reikšmes, visuma. Tai visuma pramonės įmo¬nių, šalies miestų, įmonių darbininkų, gaminių partijų ir t. t. Pirminiai nedalijami visumos elementai (objektai ir reiškiniai), turintys
bendrų visumos požymių, yra vadinami visumos vienetais (pramonės įmonė, miestas, darbininkas, gaminys ir t. t.).
Jeigu vienas arba keli bendri požymiai yra esminiai, statistinė visuma vadinama kokybiškai vienarūše. Visuma, kurią sudaro ne vieno tipo elementai, yra nevienarūšė. Pažymėtina, kad ta pati visuma vienu požiūriu kokybiškai vienarūšė, kitu – ne.
Visumos vienarūšiškumą nulemia vidinių priežasčių ir bendrų sąlygų įtaka. Kitaip tariant, kiekviena statistinė visuma visais atžvilgiais negali būti vienarūšė. Visumoje visada galima išskirti kokybiškai skirtingas grupes, kurių vienetai turi kiekybinių bei daugiau ar mažiau reikšmingų kokybinių skirtumų. Pavyzdžiui, aukštosios mokyklos studentai, kaip statistinė visuma, pagal mokymo formas sudaro tris grupes: dieninio, vakarinio ir neakivaizdinio, todėl turi skirtingų požymių.
Reiškinys, kai visumos arba jos dalių elementai skiriasi vienas nuo kito vieno ar kito požymio reikšmėmis, t. y. kai jos reikšmės svyruoja, kinta, yra vadinamas variacija. Pavyzdžiui, dieninio skyriaus studentai gali skirtis amžiumi, pažangumu, gali gauti stipendiją arba jos negauti ir t. t. Variacija – svarbus statistinės visumos bruožas. Jeigu nebūtų variacijos, nereikėtų statistikos. Variacija atsiranda dėl įvairių priežasčių poveikio reiškiniui. Ji pasireiškia tiek laike, tiek erdvėje.
Statistinis rodiklis – skaitmeninė charakteristika, parodanti visuomeninio reiškinio tam tikrą savybę ar ypatybę konkrečiomis vietos ir laiko sąlygomis.
Jeigu statistinis rodiklis .atspindi tam tikrą reiškinį (pvz., pramonės įmonės realizuotos produkcijos apimtį), tai jis vadinamas individualiu. Todėl rodikliai dažnai vadinami tiesiog statistiniais duomenimis.
Jeigu rodiklis charakterizuoja reiškinių visumą (šalies gyventojus, pramonės įmones ir t. t.), jis vadinamas apibendrinančiu.
Nors statistiniai rodikliai išreiškia kiekybinę reiškinių pusę, tačiau kartu atspindi ir kokybinę. Pavyzdžiui, darbo našumo plano įvykdymo procentas kartu apibūdina įmonės darbo kokybę. Vadinasi, statistiniuose rodikliuose atsispindi visuomeninių reiškinių kiekybės ir kokybės vienybė.
Statistinių rodiklių turinys nustatomas iš anksto, t. y. paruošiamajame statistinio tyrimo etape. Tokiu atveju paminėtini rodikliai, kategorijos, kurie apibūdina vieno tipo reiškinių bendras savybes, bendrus požymius (mažmeninė prekių apyvarta, vidutinis sąrašinis darbuotojų skaičius, nacionalinės pajamos, vidutinis mėnesinis darbo užmokestis ir t. t.). Statistikos teorija parengia šių rodiklių skaičiavimo metodiką, kuria remiantis gaunami konkretūs rodikliai.
Turinys konkretinamas ir kiekybinė charakteristika gaunama statistinės medžiagos suvedimo etape ir yra statistikos praktinės veiklos rezultatas.
Socialiniams ekonominiams reiškiniams, jų apimčiai, lygiui, dinamikai bei santykiams atvaizduoti statistika naudoja rodiklių visumą, kuri vadinama statistinių rodiklių sistema.
Statistiniai rodikliai skiriasi nuo planinių tuo, kad jie yra objektyvūs, negali būti pakeisti, nes atspindi tai, kas jau įvyko, kas yra, kas pasiekta. Tačiau ne visi reiškiniai planuojami; daugelis iš jų turi būti skaičiuojami, pvz., natūralaus gyventojų judėjimo rodikliai skaičiuojami, tačiau neplanuojami. Dėl šios priežasties statistinių rodiklių sistema yra platesnė už planinių rodiklių sistemą.
Rodiklių įvairovė reikalauja juos klasifikuoti. Yra žinomi keli rodiklių klasifikavimo požymiai:
1. Gavimo būdas (pirminiai ir išvestiniai rodikliai).
2. Statistinė prigimtis – absoliutinių bei santykinių dydžių rodikliai ir vidurkiai; jie gali išreikšti reiškinių apimtis, santykius arba tipišką jų lygį.
3. Laiko charakteristika (momentiniai ir intervaliniai rodikliai parodo reiškinio lygį apibrėžta data arba jo apimtį, vidutinį lygį per tam tikrą laikotarpį).
Pagal socialinį ekonominį turinį rodikliai skirstomi į gyventojų skaičiaus, visuomenės darbo išteklių, visuomeninio produkto gamybos, nacionalinių pajamų, gyvenimo lygio, gyventojų sveikatos apsaugos ir kt. Tokią rodiklių klasifikaciją nagrinėja ekonominė statistika.
IŠVADOS
1. Savo dalykui tyrinėti statistika parengia ir pritaiko įvairius metodus, kurių visuma sudaro statistinę metodologiją. Tai, koks metodas bus naudojamas statistiniuose tyrimuose, lemia jų užduotys ir pradinės informacijos pobūdis.
2. Statistinio tyrimo tikslas – apibendrintų duomenų gavimas ir siekimas atskleisti tų reiškinių visumos bendrąsias savybes konkrečiomis vietos ir laiko sąlygomis.
3. Atliekant statistinius tyrimus tenka išskirti šiuos tyrimo etapus, kuriuose statistika naudoja savo specifinius metodus:
• Statistinis stebėjimas (faktų registravimo ir apskaitos metodai);
• Statistinės medžiagos suvedimas, t.y. surinktų duomenų kontrolės, rūšiavimo, grupavimo metodai, apibendrinančių rodiklių apskaičiavimo, statistinių lentelių suvedimo bei grafikų vaizdavimo metodai;
• Statistinės medžiagos analizė, kuri gali būti dviejų lygių: gautų duomenų tikslumo vertinimas (parametrų įvertinimo, statistinių hipotezių patikrinimo metodai) ir dalykinė tiriamo objekto būklės analizė;
• Analizės rezultatų įvertinimas. Pateikiamos išvados apie tiriamo reiškinio objekto būklę (ekonominis interpretavimas), prognozės ateičiai, gali būti rekomendacijos.
// // // //
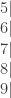

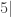
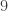
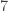
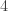
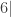
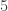




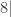


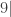

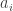 , o taip pat esama galimybių apskaičiuoti kiekvienos iš jų teorinę tikimybę
, o taip pat esama galimybių apskaičiuoti kiekvienos iš jų teorinę tikimybę  . Visi šie duomenys paprastai suvedami į vadinamąją dažnių lentelę, panašią į anksčiau pateiktąją, tik turinčią dar ir trečią eilutę, skirtą teorinėms reikšmių tikimybėms
. Visi šie duomenys paprastai suvedami į vadinamąją dažnių lentelę, panašią į anksčiau pateiktąją, tik turinčią dar ir trečią eilutę, skirtą teorinėms reikšmių tikimybėms  Stebimasis empirinis reikšmių skirstinys iš esmės nesiskiria nuo parinktojo teorinio modelio ir yra su juo statistiškai suderinamas
Stebimasis empirinis reikšmių skirstinys iš esmės nesiskiria nuo parinktojo teorinio modelio ir yra su juo statistiškai suderinamas Stebimasis empirinis reikšmių skirstinys iš esmės skiriasi nuo parinktojo teorinio modelio ir yra su juo statistiškai nesuderinamas
Stebimasis empirinis reikšmių skirstinys iš esmės skiriasi nuo parinktojo teorinio modelio ir yra su juo statistiškai nesuderinamas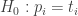
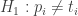
 ):
):
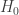 teisinga, ši KS turi chi-kvadrato skirstinį su tam tikru
teisinga, ši KS turi chi-kvadrato skirstinį su tam tikru  laisvės laipsnių skaičiumi, kuris priklauso nuo to, kokiu konkrečiu būdu buvo apskaičiuojamos tikimybės
laisvės laipsnių skaičiumi, kuris priklauso nuo to, kokiu konkrečiu būdu buvo apskaičiuojamos tikimybės 
 , tai H0 atmetama, kai x viršija turimą laisvės laipsnių skaičių atitinčią kritinę reikšmę (KR), kurią galima arba rasti statistikos knygų prieduose, arba apskaičiuoti su Excel remiantis žinomu laisvės laipsnių skaičiumi
, tai H0 atmetama, kai x viršija turimą laisvės laipsnių skaičių atitinčią kritinę reikšmę (KR), kurią galima arba rasti statistikos knygų prieduose, arba apskaičiuoti su Excel remiantis žinomu laisvės laipsnių skaičiumi  )
) )
) ; laisvės laipsnių skaičius būtų
; laisvės laipsnių skaičius būtų 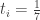 „išprotavome“ nesinaudodami nė vieno parametro empiriniu įverčiu, taigi, h = 0), todėl pagal imties duomenis gaunama p-reikšmė būtų p = 0,187232. Tad nulinei hipotezei atmesti nebūtų visiškai tvirto pamato (kone 19% siekianti pirmos rūšies klaidos rizika dar yra gerokai per didelė), ir turėtume sakyti, kad šios imties duomenys nepaneigia nuostatos, jog tikimybė gimti bet kurią savaitės dieną yra vienoda.
„išprotavome“ nesinaudodami nė vieno parametro empiriniu įverčiu, taigi, h = 0), todėl pagal imties duomenis gaunama p-reikšmė būtų p = 0,187232. Tad nulinei hipotezei atmesti nebūtų visiškai tvirto pamato (kone 19% siekianti pirmos rūšies klaidos rizika dar yra gerokai per didelė), ir turėtume sakyti, kad šios imties duomenys nepaneigia nuostatos, jog tikimybė gimti bet kurią savaitės dieną yra vienoda.
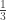 iki
iki 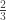 . Yra keli būdai tą įrodyti. Vienas iš populiariausių sprendimų gali būti pavaizduotas tokia schema:
. Yra keli būdai tą įrodyti. Vienas iš populiariausių sprendimų gali būti pavaizduotas tokia schema:


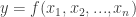 .
. ;
; , nustatyti išėjimo parametro skirstinį
, nustatyti išėjimo parametro skirstinį  arba surasti tikimybę, kad išėjimo parametro reikšmės bus duotosiose ribose, kintant elementų parametrų reikšmėms pagal skirstinius.
arba surasti tikimybę, kad išėjimo parametro reikšmės bus duotosiose ribose, kintant elementų parametrų reikšmėms pagal skirstinius.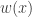 gaunami naudojant vienodos tikimybės skaičius ir sprendžiant lygtį parametro
gaunami naudojant vienodos tikimybės skaičius ir sprendžiant lygtį parametro 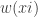 . Naudojami ir kitokie atsitiktinių skaičių gavimo būdai. Visos šiuolaikinės elektroninės skaičiavimo mašinos turi programas, leidžiančias generuoti pseudoatsitiktinius skaičius, pasiskirsčiusius pagal norimą skirstinį. Nepriklausomai nuo atsitiktinių skaičių gavimo būdo apie jų kokybę galima spręsti iš gauto statistinio skirstinio sutapimo su norimu teoriniu skirstiniu. Apie skirstinių sutapimo laipsnį sprendžiama iš sutapimo kriterijų. Praktikoje plačiausiai naudojami Pirsono ir Kolmagorovo sutapimo kriterijai.
. Naudojami ir kitokie atsitiktinių skaičių gavimo būdai. Visos šiuolaikinės elektroninės skaičiavimo mašinos turi programas, leidžiančias generuoti pseudoatsitiktinius skaičius, pasiskirsčiusius pagal norimą skirstinį. Nepriklausomai nuo atsitiktinių skaičių gavimo būdo apie jų kokybę galima spręsti iš gauto statistinio skirstinio sutapimo su norimu teoriniu skirstiniu. Apie skirstinių sutapimo laipsnį sprendžiama iš sutapimo kriterijų. Praktikoje plačiausiai naudojami Pirsono ir Kolmagorovo sutapimo kriterijai. tikslumo tyrimui atlikti.
tikslumo tyrimui atlikti.
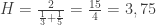
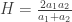
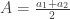 ,
,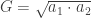 .
.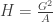 .
.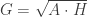 .
. ,
, ,
,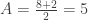 ,
,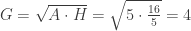 .
.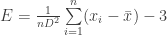
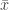 – matavimų aritmetinis vidurkis, D – matavimų dispersija. Jei trejetas nebūtų atimamas, Gauso skirstinio kreivės piko aštrumas būtų lygus trims.
– matavimų aritmetinis vidurkis, D – matavimų dispersija. Jei trejetas nebūtų atimamas, Gauso skirstinio kreivės piko aštrumas būtų lygus trims.


 . Teorinio nežinomo vidurkio m įvertis yra imties vidurkis
. Teorinio nežinomo vidurkio m įvertis yra imties vidurkis 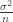 , standartinis nuokrypis –
, standartinis nuokrypis – 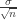 , standartinis nuokrypio įvertis yra
, standartinis nuokrypio įvertis yra  ir žymimas
ir žymimas 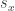 . Įvertis
. Įvertis  .
.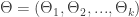 įverčio
įverčio 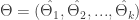 kintamumas. Jis vertinamas kovariacijų matrica
kintamumas. Jis vertinamas kovariacijų matrica  (žr. žemiau esantį pav.).
(žr. žemiau esantį pav.).
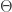 yra vertinamas Bajeso metodu, tai
yra vertinamas Bajeso metodu, tai 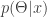 skirstinį arba naudojantis tikslia
skirstinį arba naudojantis tikslia 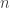 dydžio imties reikšmių galima sugeneruoti
dydžio imties reikšmių galima sugeneruoti 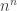 skirtingų
skirtingų  dydžio imčių. Ši procedūra vadinama visa pakartotine atranka(complete resampling).
dydžio imčių. Ši procedūra vadinama visa pakartotine atranka(complete resampling).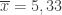 ,
,  . Iš 1, 6, 9 reikšmių galima sudaryti
. Iš 1, 6, 9 reikšmių galima sudaryti 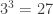 skirtingų imčių. Žemiau lentelėje pateikti kiekvienos šių imčių vidurkis ir standartinis nuokrypis.
skirtingų imčių. Žemiau lentelėje pateikti kiekvienos šių imčių vidurkis ir standartinis nuokrypis.
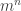 imčių.
imčių.