Atsitiktinai parinkta 400 žmonių ir tirta, kurią savaitės dieną kievienas iš jų yra gimę. Gauti duomenys suvesti į tokią empirinio skirstinio lentelę, paremtą absoliutiniais kokybinio požymio savaitės diena dažnumais:
 Ar šie duomenys suderinami su nuostata, kad tikimybė gimti bet kurią savaitės dieną yra vienoda (t.y. lygi 1 / 7 = 0,142857)?
Ar šie duomenys suderinami su nuostata, kad tikimybė gimti bet kurią savaitės dieną yra vienoda (t.y. lygi 1 / 7 = 0,142857)?
Tai vienas iš paprastesnių suderinamumo uždavinių, nes visus empirinius kokybinio požymio (savaitės diena) reikšmių dažnumus tenka lyginti tik su vienu, pastoviu „predikatu“, apspręstu pastovios tikimybės 1/7. Didžiumoje kitų suderinamumo uždavinių kiekvienos iš reikšmių tikimybė būna vis kitokia, tad ir lyginimo „predikatai“ įvairuoja.
Jeigu nuostata, kad tikimybė gimti bet kurią savaitės dieną yra pastovi ir lygi 1 / 7 = 0,142857 teisinga,tai bet kurią savaitės dieną „teoriškai“ turėtų būti gimę po… 0,142857*400 = 57, 14286 žmogaus! Sprendžiant klausimą apie šių konkrečių duomenų suderinamumą su minėta nuostata, būtent su šiuo „predikatu“ ir tektų lyginti turimus empirinius absoliutinius dažnumus. Tačiau – kaip lyginti?
Suderinamumo uždavinių statistinis modelis bendru atveju būtų toks:
Situacija. Imtis atsitiktinė, tiriamas požymis – diskretusis (jis gali būti kokybinis, ranginis arba kiekybinis diskretusis; jei jis – kiekybinis tolydusis požymis, tai diskretizuojamas dirbtinai, paprastai – grupuojant reikšmes intervalais). Imtyje jis įgauna k skirtingų reikšmių. Eksperimentiškai yra nustatytas kiekvienos (i-tosios; i = 1, 2 … k) iš tų reikšmių absoliutinis dažnumas 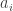

Statistines prielaidas šiuo atveju suprantamiau yra suformuluoti žodžiais. Bendru atveju jas galima apibūdinti
maždaug taip:


Formalizuotas statistinių prielaidų „pavaizdavimas“ taip pat galimas: tada nulinėje hipotezėje teigtume, kad visiems i = 1, 2 … k požymio skirtingų reikšmių proporcijos pi populiacijoje, iš kurios paimta imtis, esmingai nesiskiria nuo jų teorinių tikimybių
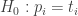
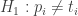
Kriterijaus statistika skaičiuojama tokių dydžių suma (pažymėkime ją 

Kai 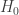

empiriniais įverčiais naudotasi apskaičiuojant
skaičių gautosios

Prielaidų vertinimas remiasi apskaičiuotąja 
KR = CHIINV( 
Kita vertus su Excel lengva apskaičiuoti ir gautąjį
p = CHIDIST(
Jeigu p-reikšmė gaunama nedidelė (paprastai – mažesnė už tradicinius reikšmingumo lygmenis),
Jeigu grįžtume prie šio post’o pradžioje pateikto pavyzdžio ir aptartu būdu jam apskaičiuotume kriterijaus statistiką, tai gautume 
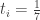
Išvada. Suderinamumo uždavinius tenka spręsti ir siekiant patikrinti, ar eksperimento metu gautų duomenų empirinis
skirstinys atitinka kokį nors hipotetinį teorinį skirstinį (pvz., normalųjį – tai dažna problema).

17 gruodžio, 2009 2:26 pm |
Siu duomenu netikslus atspindejimas tikimybes tikrodo, kad reikia ddinti imties diduma ir tada artesimne prie tos teorines tikimybes.